Computer Vision with EOL Images
I am currently working as a contractor for the Encyclopedia of Life database at the Smithsonian National Museum of Natural History in Washington, DC. My work includes testing different computer vision methods (object detection, image classification) to do customized, large-scale image processing for Encyclopedia of Life v3 database images.
To see technical details and code used in this project, check out the Computer Vision With EOL Images GitHub Repository.

Images a-c are hosted by Encyclopedia of Life (a. Choeronycteris mexicana licensed under CC BY 2.0, b. Hippotion celerio licensed under CC BY-NC-SA 3.0, c. Cuculus solitarius (left) and Cossypha caffra (right) licensed under CC BY-SA 2.0).
I’m using three object detection frameworks (YOLO, Faster-RCNN and SSD) to perform customized, large-scale image processing for different groups of animals (birds, bats, butterflies & moths, beetles, frogs, carnivores, snakes & lizards) found in Encyclopedia of Life. The three frameworks differ in their speeds and accuracy: YOLO has been found to be the fastest but least accurate, while Faster RCNN was found to be the slowest but most accurate, with MobileNet SSD falling somewhere in between (Lin et al. 2017, Hui 2018, Redmon and Farhadi 2018).
After initial tests, the model with the best trade-off between speed and accuracy for each group is selected to generate final cropping data for EOL images. The location and dimensions of the detected animals within each framework are used to crop images to square dimensions that are centered and padded around the detection box. For birds, pre-trained object detection models were used. For bats and butterflies & moths, object detection models were custom-trained to detect one class (either bats or butterflies & moths) using EOL user-generated cropping data (square coordinates around animal(s) of interest within each photo). For beetles, frogs, carnivores and snakes & lizards, object detection models were custom-trained to detect all classes simultaneously using EOL user-generated cropping data.
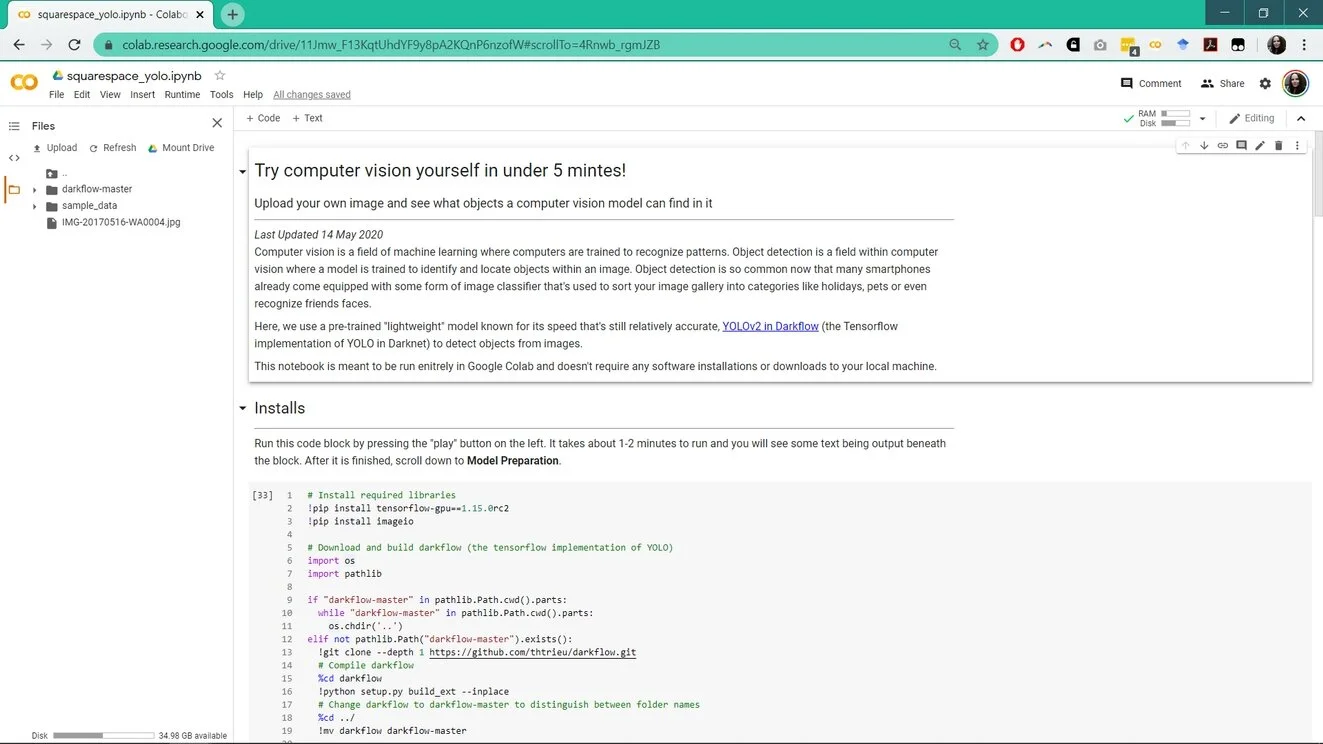
Have 5 minutes and want to try computer vision yourself?
DIY Computer Vision in 5 minutes
- Click this button
 to open a computer vision tool that runs directly in your web browser.*
to open a computer vision tool that runs directly in your web browser.*
a. You will get a message from Google that the service isn’t authored by them, click "Run Anyway." - The computer vision tool will open in your browser (see screenshot below).
- Then, follow the directions in the notebook and see what objects YOLOv2 can detect from your images!
The computer vision model used, YOLOv2, is quick and lightweight but not always the most accurate. Some cues in the pictures of the guinea pigs above lead YOLO to predict that the pictures were of a person or bird. I've also seen it mispredict a bird in a nest (that looked a lot like pita bread) to be a sandwich. Try it out and see what correct and funny predictions you get!
*It uses the programming language, Python, running in a Jupyter Notebook via Google Colaboratory, "a free cloud service...for machine-learning education and research".
Bird, person or guinea pig? Try out the computer vision model, YOLOv2 on your own images and see what it’s able to identify (or not). Top: "Poopsie Goes Fishing" by bickbyro is licensed under CC BY-NC-SA 2.0. Bottom: "HEy, IT's yOu! (Explored)" by andymiccone is licensed under CC0 1.0.


Have another 5 minutes and want to try automated image augmentation?
DIY Automated Image Augmentation in 5 minutes
- Click this button to open an image augmentation tool that runs directly in your web browser.
a. You will get a message from Google that the service isn’t authored by them, click "Run Anyway." - The image augmentation tool will open in your browser (see screenshot below).
- Then, follow the directions in the notebook and see augmented versions (rotated, flipped, blurred, etc) of your images!
Image augmentation is a technique used to increase image dataset size and diversity used for training computer vision models. It reduces overfitting and increases the ability of a model to generalize to broader datasets. Try it out and see the pretty colored, rotated versions of your images that result!
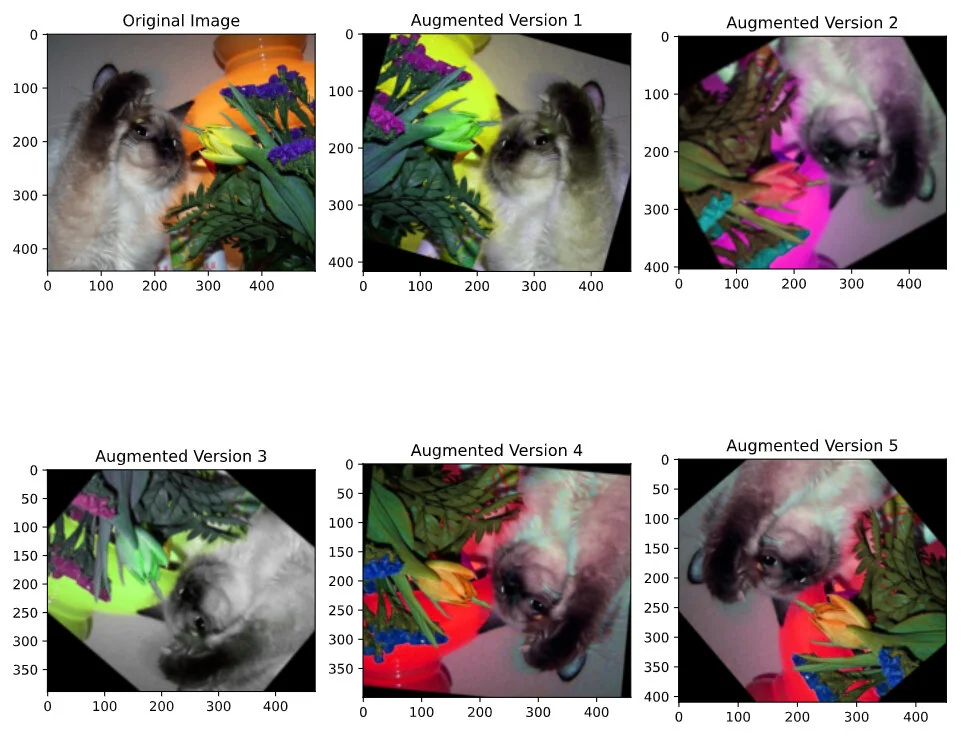
Augmented versions of an image used to increase dataset size and diversity for training computer vision models that are better able to generalize to broad datasets. Original Image: "Funny strikes the tulip!" by Buntekuh is licensed under CC BY-NC-SA 2.0
Good boy detector confirmed - Max and Vixie are the best pups!

{kind=link}
{kind=link}
References
Hui 2018. Object detection: speed and accuracy comparison (Faster R-CNN, R-FCN, SSD, FPN, RetinaNet and YOLOv3). Medium. 27 March 2018.
Lin et al. 2015. Microsoft COCO: Common Objects in Context. arXiv:1405.0312.
Liu et al. 2015. SSD: Single Shot MultiBox Detector.
Medeiros 2020. For very helpful, detailed UI and guinea pig image feedback.
Redmon and Farhadi 2018. YOLOv3: An Incremental Improvement.
Ren et al. 2016. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks.